
|
|
||
|
My research interests are in the areas of Computer Vision, Machine Learning and Ubiquitous Computing. |
|
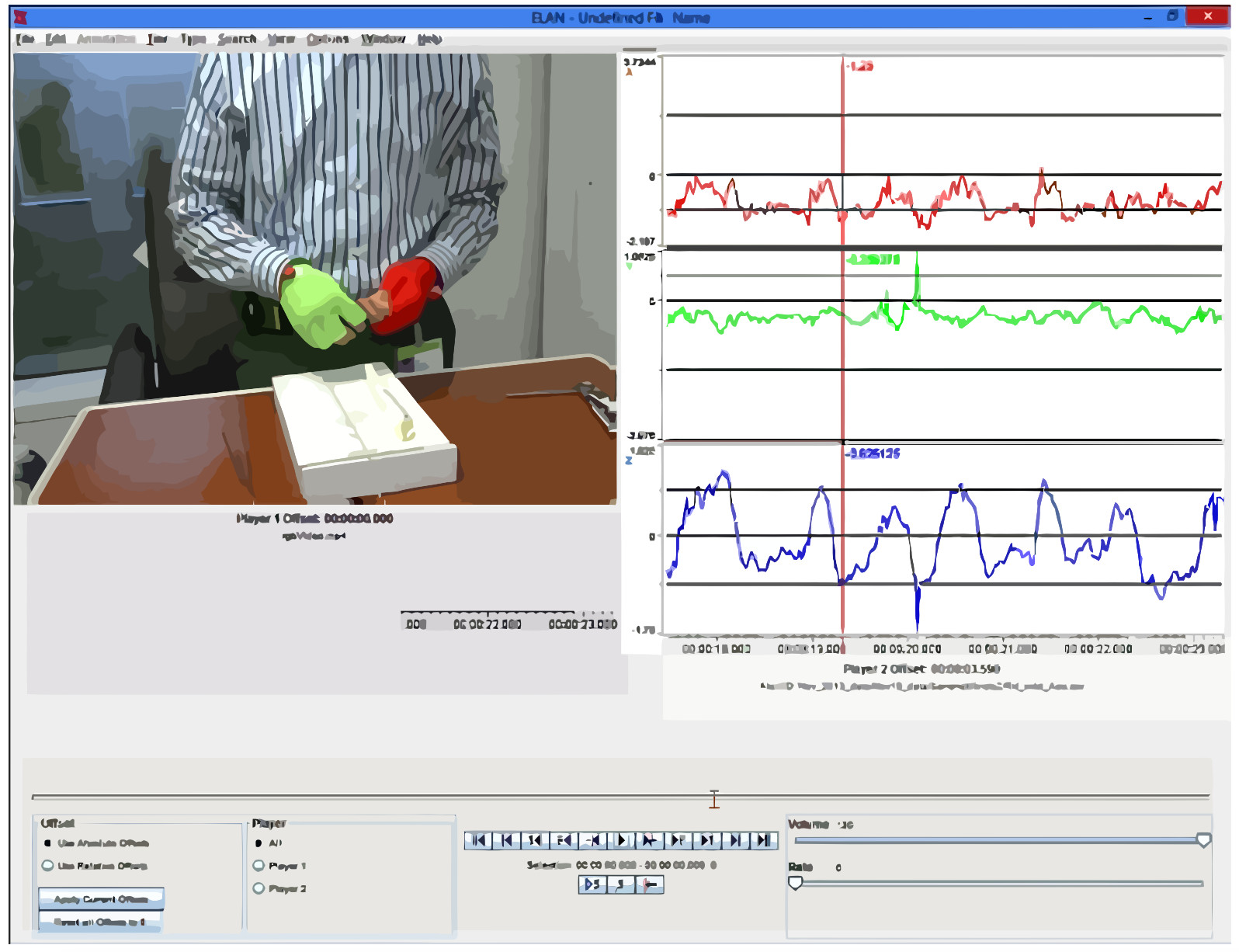
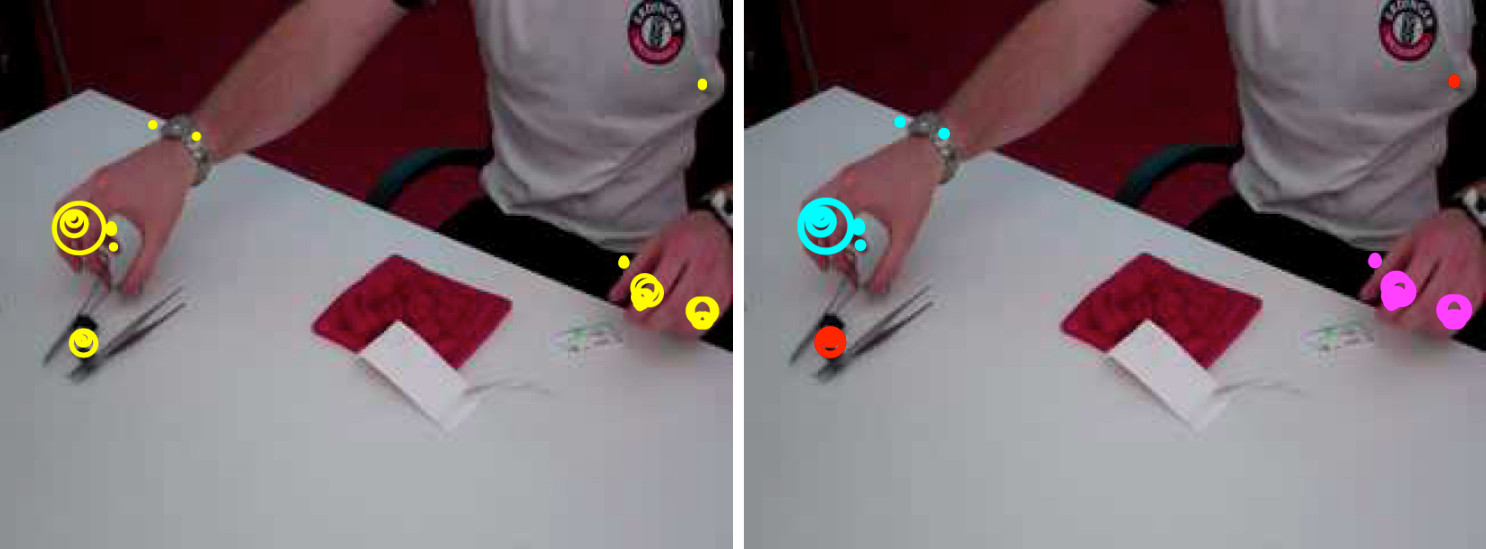
Basic surgical skills of suturing and knot tying are an essential part of medical training. Having an automated system for surgical skills assessment could help save experts time and improve training efficiency. There have been some recent attempts at automated surgical skills assessment using either video analysis or acceleration data. In this paper, we present a novel approach for automated assessment of OSATS like surgical skills and provide an analysis of different features on multi-modal data (video and accelerometer data). We conduct a large study for basic surgical skill assessment on a dataset that contained video and accelerometer data for suturing and knot-tying tasks. We introduce “entropy based” features – Approximate Entropy (ApEn) and Cross-Approximate Entropy (XApEn), which quantify the amount of predictability and regularity of fluctuations in time-series data. The proposed features are compared to existing methods of Sequential Motion Texture (SMT), Discrete Cosine Transform (DCT) and Discrete Fourier Transform (DFT), for surgical skills assessment. Results: We report average performance of different features across all applicable OSATS-like criteria for suturing and knot tying tasks. Our analysis shows that the proposed entropy-based features outperform previous state-of-the-art methods using video data, achieving average classification accuracies of 95.1% and 92.2% for suturing and knot tying, respectively. For accelerometer data, our method performs better for suturing achieving 86.8% average accuracy. We also show that fusion of video and acceleration features can improve overall performance for skill assessment.Here is the IJCARS 2018 journal paper
|
|
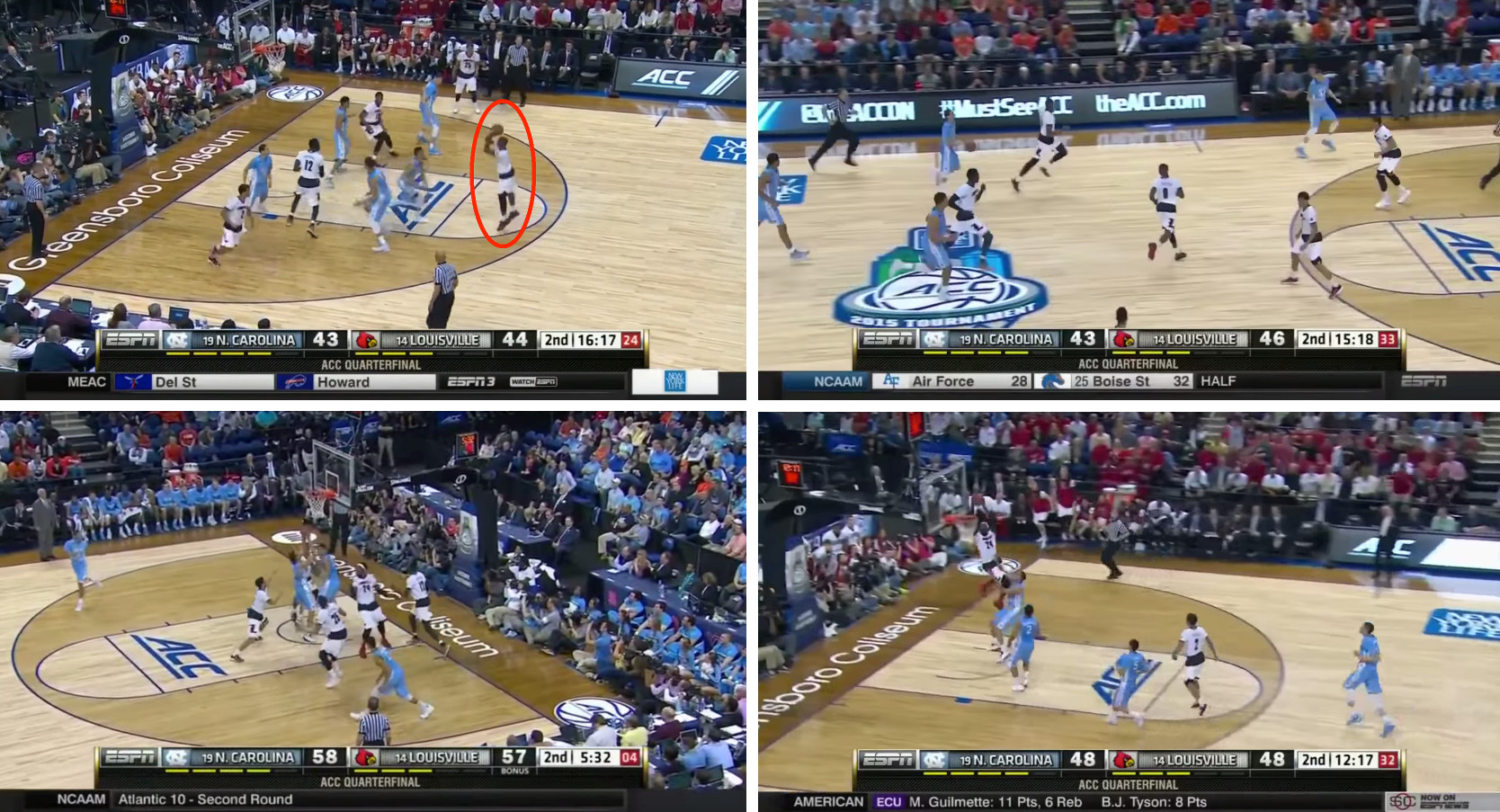
The massive growth of sports videos has resulted in a need for automatic generation of sports highlights that are comparable in quality to the hand-edited highlights produced by broadcasters such as ESPN. Unlike previous works that mostly use audio-visual cues derived from the video, we propose an approach that additionally leverages contextual cues derived from the environment that the game is being played in. The contextual cues provide information about the excitement levels in the game, which can be ranked and selected to automatically produce high-quality basketball highlights. We introduce a new dataset of 25 NCAA games along with their play-by-play stats and the ground-truth excitement data for each basket. We explore the informativeness of five different cues derived from the video and from the environment through user studies. Our experiments show that for our study participants, the highlights produced by our system are comparable to the ones produced by ESPN for the same games.Here is the ACM MM 2016 Project Webpage (PDF and Video Demo)Accepted for oral presentation |

|
Routine evaluation of basic surgical skills in medical schools requires considerable time and effort from supervising faculty. For each surgical trainee, a supervisor has to observe the trainees inperson. Alternatively, supervisors may use training videos, which reduces some of the logistical overhead. All these approaches however are still incredibly time consuming and involve human bias. In this paper, we present an automated system for surgical skills assessment by analyzing video data of surgical activities. Method: We compare different techniques for video-based surgical skill evaluation. We use techniques that capture the motion information at a coarser granularity using symbols or words, extract motion dynamics using textural patterns in a frame kernel matrix, and analyze fine-grained motion information using frequency analysis. We were successfully able to classify surgeons into different skill levels with high accuracy. Our results indicate that fine-grained analysis of motion dynamics via frequency analysis is most effective in capturing the skill relevant information in surgical videos. Conclusion: Our evaluations show that frequency features perform better than motion texture features, which in-turn perform better than symbol/word based features. Put succinctly, skill classification accuracy is positively correlated with motion granularity as demonstrated by our results on two challenging video datasets.Here is the IJCARS 2016 journal paper
|
|
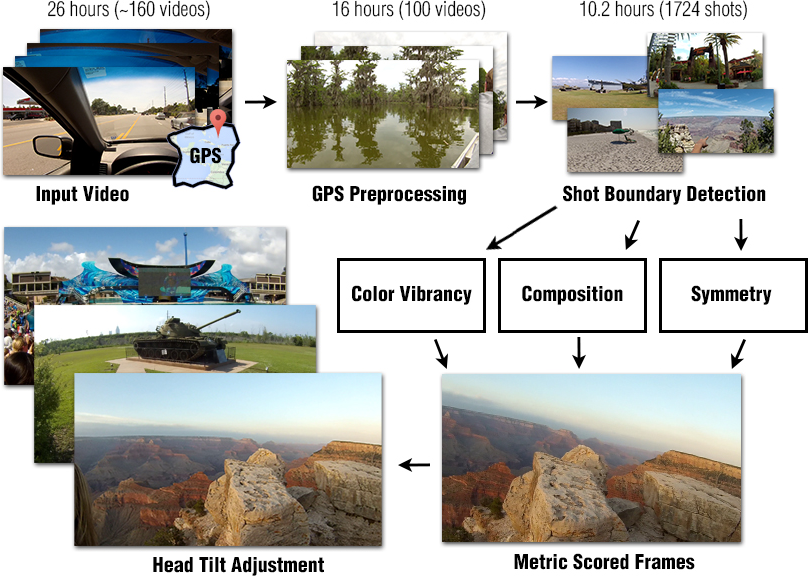
We present an approach for identifying picturesque highlights from large amounts of egocentric video data. Given a set of egocentric videos captured over the course of a vacation, our method analyzes the videos and looks for images that have good picturesque and artistic properties. We introduce novel techniques to automatically determine aesthetic features such as composition, symmetry and color vibrancy in egocentric videos and rank the video frames based on their photographic qualities to generate highlights. Our approach also uses contextual information such as GPS, when available, to assess the relative importance of each geographic location where the vacation videos were shot. Furthermore, we specifically leverage the properties of egocentric videos to improve our highlight detection. We demonstrate results on a new egocentric vacation dataset which includes 26.5 hours of videos taken over a 14 day vacation that spans many famous tourist destinations and also provide results from a user-study to access our results.Here is the WACV 2016 paper
|

|
We present an automated framework for visual assessment of the expertise level of surgeons using the OSATS (Objective Structured Assessment of Technical Skills) criteria. Video analysis techniques for extracting motion quality via frequency coefficients are introduced. The framework is tested on videos of medical students with different expertise levels performing basic surgical tasks in a surgical training lab setting. We demonstrate that transforming the sequential time data into frequency components effectively extracts the useful information differentiating between different skill levels of the surgeons. The results show significant performance improvements using DFT and DCT coefficients over known state-of-the-art techniques.Here is the MICCAI 2015 paper
|

|
We present a method to analyze images taken from a passive egocentric wearable camera along with the contextual information, such as time and day of week, to learn and predict everyday activities of an individual. We collected a dataset of 40,103 egocentric images over a 6 month period with 19 activity classes and demonstrate the benefit of state-of-the-art deep learning techniques for learning and predicting daily activities. Classification is conducted using a Convolutional Neural Network (CNN) with a classification method we introduce called a late fusion ensemble. This late fusion ensemble incorporates relevant contextual information and increases our classification accuracy. Our technique achieves an overall accuracy of 83.07% in predicting a person's activity across the 19 activity classes. We also demonstrate some promising results from two additional users by fine-tuning the classifier with one day of training data.Here is the ISWC 2015 Project Webpage (with PDF) |

|
We present a technique that uses images, videos and sensor data taken from first-person point-of-view devices to perform egocentric field-of-view (FOV) localization. We define egocentric FOV localization as capturing the visual information from a person’s field-of-view in a given environment and transferring this information onto a reference corpus of images and videos of the same space, hence determining what a person is attending to. Our method matches images and video taken from the first-person perspective with the reference corpus and refines the results using the first-person’s head orientation information obtained using the device sensors. We demonstrate single and multi-user egocentric FOV localization in different indoor and outdoor environments with applications in augmented reality, event understanding and studying social interactions.Here is the WACV 2015 Project Webpage (PDF, Poster and Video Demo)We won the best paper award at WACV 2015 |

|
The pervasiveness of mobile cameras has resulted in a dramatic increase in food photos, which are pictures reflecting what people eat. In this paper, we study how taking pictures of what we eat in restaurants can be used for the purpose of automating food journaling. We propose to leverage the context of where the picture was taken, with additional information about the restaurant, available online, coupled with state-of-the-art computer vision techniques to recognize the food being consumed. To this end, we demonstrate image-based recognition of foods eaten in restaurants by training a classifier with images from restaurant’s online menu databases. We evaluate the performance of our system in unconstrained, real-world settings with food images taken in 10 restaurants across 5 different types of food (American, Indian, Italian, Mexican and Thai).Here is the WACV 2015 Project Webpage (PDF and Poster). |
|
We present a fully automated framework for video based surgical skill assessment that incorporates the sequential and qualitative aspects of surgical motion in a data-driven manner. We replicate Objective Structured Assessment of Technical Skills (OSATS) assessments, which provides both an overall and in-detail evaluation of basic suturing skills required for surgeons. Video analysis techniques are introduced that incorporate sequential motion aspects into motion textures. We also demonstrate significant performance improvements over standard bag-ofwords and motion analysis approaches. We evaluate our framework in a case study that involved medical students with varying levels of expertise performing basic surgical tasks in a surgical training lab setting.Here is the M2CAI 2014 paper
|

|
We present data-driven techniques to augment Bag of Words (BoW) models, which allow for more robust modeling and recognition of complex long-term activities, especially when the structure and topology of the activities are not known a priori. Our approach specifically addresses the limitations of standard BoW approaches, which fail to represent the underlying temporal and causal information that is inherent in activity streams. In addition, we also propose the use of randomly sampled regular expressions to discover and encode patterns in activities. We demonstrate the effectiveness of our approach in experimental evaluations where we successfully recognize activities and detect anomalies in four complex datasets.Here is the CVPR 2013 Project Webpage (PDF and Code). |
|
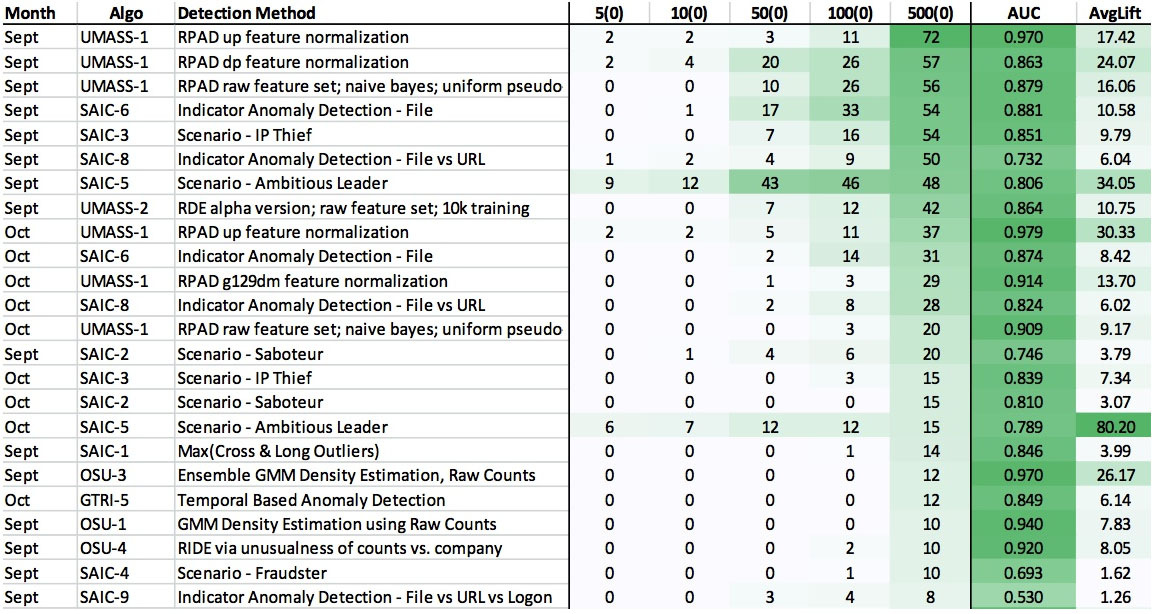
This paper reports on methods and results of an applied research project by a team consisting of SAIC and four universities to develop, integrate, and evaluate new approaches to detect the weak signals characteristic of insider threats on organizations’ information systems. Our system combines structural and semantic information from a real corporate database of monitored activity on their users’ computers to detect independently developed red team inserts of malicious insider activities. We have developed and applied multiple algorithms for anomaly detection based on suspected scenarios of malicious insider behavior, indicators of unusual activities, high-dimensional statistical patterns, temporal sequences, and normal graph evolution. Algorithms and representations for dynamic graph processing provide the ability to scale as needed for enterpriselevel deployments on real-time data streams. We have also developed a visual language for specifying combinations of features, baselines, peer groups, time periods, and algorithms to detect anomalies suggestive of instances of insider threat behavior. We defined over 100 data features in seven categories based on approximately 5.5 million actions per day from approximately 5,500 users. We have achieved area under the ROC curve values of up to 0.979 and lift values of 65 on the top 50 user-days identified on two months of real data.Here is the KDD 2013 paper
|
|
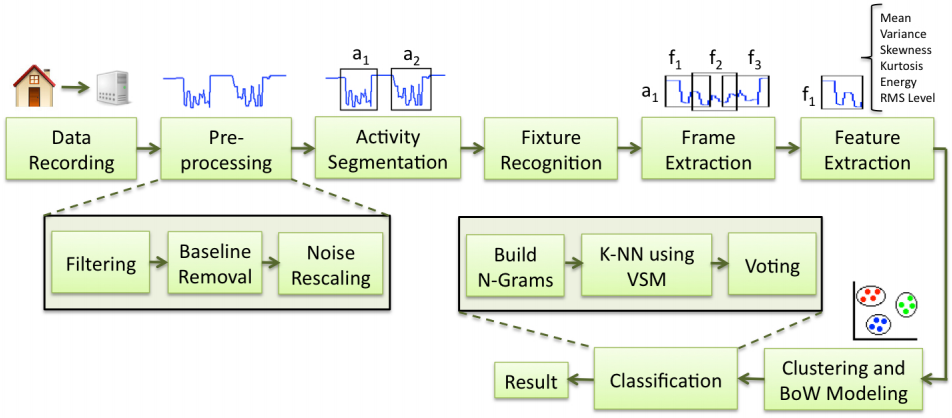
Activity recognition in the home has been long recognized as the foundation for many desirable applications in fields such as home automation, sustainability, and healthcare. However, building a practical home activity monitoring system remains a challenge. Striking a balance between cost, privacy, ease of installation and scalability continues to be an elusive goal. In this paper, we explore infrastructure-mediated sensing combined with a vector space model learning approach as the basis of an activity recognition system for the home. We examine the performance of our single-sensor water-based system in recognizing eleven high-level activities in the kitchen and bathroom, such as cooking and shaving. Results from two studies show that our system can estimate activities with overall accuracy of 82.69% for one individual and 70.11% for a group of 23 participants. As far as we know, our work is the first to employ infrastructuremediated sensing for inferring high-level human activities in a home setting.Here is the UbiComp 2012 paper
|

|
This project aims at recognizing anomalous activities from aerial videos. My work is a part of the Persistent Stare Exploitation and Analysis System (PerSEAS) research program which aims to develop software systems that can automatically and interactively discover actionable intelligence from airborne, wide area motion imagery (WAMI) in complex urban environments.A glimpse of this project can be seen here. |
|
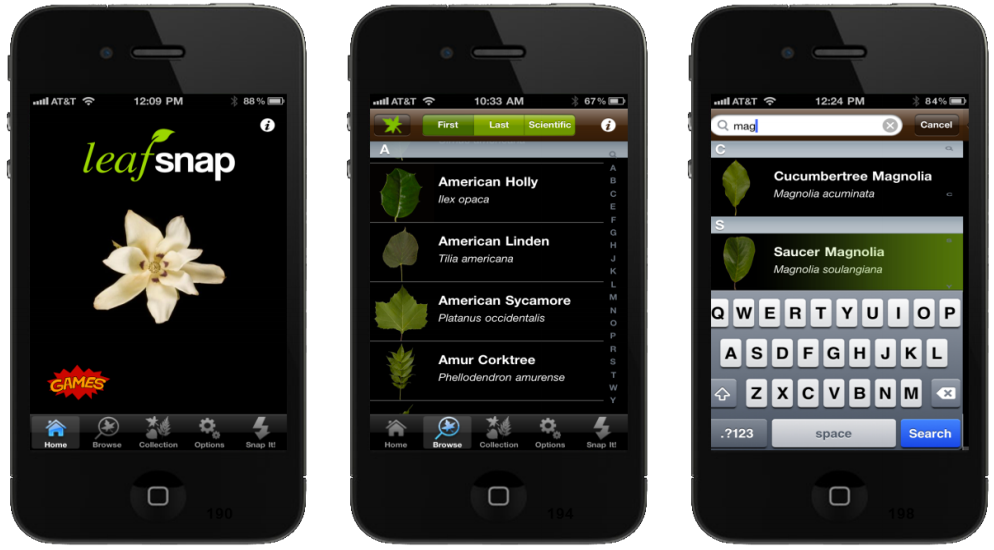
This project aims to simplify the process of plant species identification using visual recognition software on mobile devices such as the iPhone. This work is part of an ongoing collaboration with researchers at Columbia University, University of Maryland and the Smithsonian Institution. My major contribution to this project was the server's database integration and management. I also worked on stress-testing the backend server to improve its performance and scalability.The free iPhone app can be downloaded from the app-store. Here is the project webpage and here is a video explaining the app's usage. Finally, Leafsnap in the news! |
|
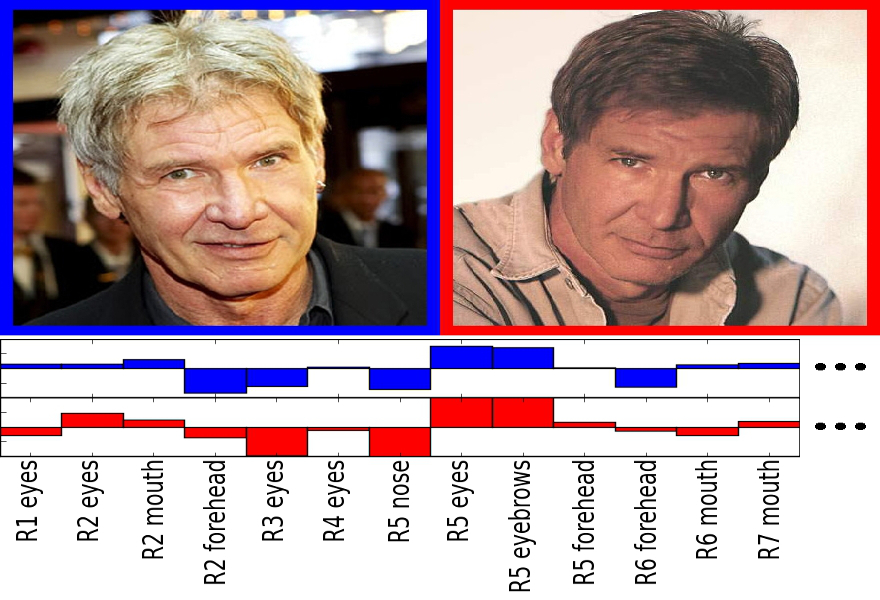
The project involves face verification in uncontrolled settings with non-cooperative subjects. The method is based on attribute (binary) classifiers that are trained to recognize the degrees of various visual attributes like gender, race, age, etc. Here is the project page.I was a part of this research at Columbia University from December 2009 to May 2010. I mainly worked on Boosting to improve the classifiers' performance. |

|
The choice of the object representation is crucial for an effective performance of cognitive tasks such as object recognition, fixation, etc. Face recognition is an example of advanced object recognition. In our project we demonstrate the use of Gabor wavelets for efficient face representation. Face recognition is influenced by several factors such as shape, reflectance, pose, occlusion and illumination which make it even more difficult. Today there exist many well known techniques to try to recognize a face. We want to introduce the Gabor wavelets for an efficient face recognition system simulating human perception of objects and faces. A face recognition system could greatly aid in the process of searching and classifying a face database and at a higher level help in identification of possible threats to security. The purpose of this study is to demonstrate that it is technically feasible to scan pictures of human faces and compare them with ID photos hosted in a centralized database using Gabor wavelets.This was my undergraduate thesis supervised by Dr. C. N. S. Ganesh Murthy, Principal Scientist at Mercedes-Benz Research and Development, Bangalore, India. Here is the project report
|
Environments with people are complex, with many activities and events that need to be represented and explained. The goal of scene understanding is to either determine what objects and people are doing in such complex and dynamic environments, or to know the overall happenings, such as the highlights of the scene. The context within which the activities and events unfold provides key insights that cannot be derived by studying the activities and events alone. In this thesis, we show that this rich contextual information can be successfully leveraged, along with the video data, to support dynamic scene understanding.We categorize and study four different types of contextual cues: (1) spatiotemporal context, (2) egocentric context, (3) geographic context, and (4) environmental context, and show that they improve dynamic scene understanding tasks across several different application domains.We start by presenting data-driven techniques to enrich spatio-temporal context by augmenting Bag-of-Words models with temporal, local and global causality information and show that this improves activity recognition, anomaly detection and scene assessment from videos. Next, we leverage the egocentric context derived from sensor data captured from first-person point-of-view devices to perform field-of-view localization in order to understand the user’s focus of attention. We demonstrate single and multi-user field-of-view localization in both indoor and outdoor environments with applications in augmented reality, event understanding and studying social interactions. Next, we look at how geographic context can be leveraged to make challenging “in-the-wild” object recognition tasks more tractable using the problem of food recognition in restaurants as a case-study. Finally, we study the environmental context obtained from dynamic scenes such as sporting events, which take place in responsive environments such as stadiums and gymnasiums, and show that it can be successfully used to address the challenging task of automatically generating basketball highlights. We perform comprehensive user-studies on 25 full-length NCAA games and demonstrate the effectiveness of environmental context in producing highlights that are comparable to the highlights produced by ESPN.Here is a PDF of my
dissertation
|
|
Link to my Google Scholar page.
|
|
|
|
Won the best paper award at WACV (IEEE Winter Conference on Applications of Computer Vision), Hawaii, USA (January 2015)
Received an honorable mention (2nd place) at M2CAI (Modeling and Monitoring of Computer Assisted Interventions), Boston, USA (September 2014)
2nd prizein the International IEEE Myron Zucker Undergraduate Student Design Contest (October 2006)
Undergraduate Rolling Trophy for securing the 1st Rank with the highest aggregate percentage for the 2006 engineering class (June 2006)
Email: |
vinaykb [at] google.com |
Also on: |
|

|

|

|

|
